Sandi-test问题讲解
(一)问题背景:
一、整体应用背景
武器现代化 + 增材制造
Metal AM and Weapon Modernization Programs
➤ 目标是生产一个不锈钢的小型子组件(stainless steel sub-component,CUP),大小像“方糖”那么小
➤ 该组件将作为更大组件的一部分
➤ 技术采用 金属增材制造(Metal Additive Manufacturing, AM),具体为:Laser Powder Bed Fusion (LPBF) —— 激光粉末床熔融法
对该零件的要求如下:
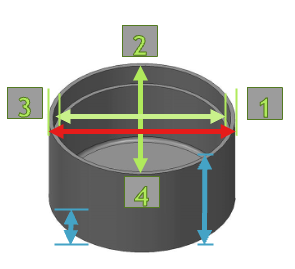
| 测量名称 | 变量名 | 公差范围 | 说明 |
|---|---|---|---|
| Lip Interior Diameter | B3_DATUM_B_LOC |
0.415" – 0.435" | 杯子内径,太小会影响装配,太大会漏配。 |
| Lip Exterior Diameter | B3_REF_OD |
0.445" – 0.469" | 杯子外径,决定零件整体尺寸,误差可能引起干涉。 |
| Floor Height (with standoff material where applicable) | C1_LOC_INSIDE_PLN |
0.049" – 0.069" | 从内部底部到参考面的高度(带支撑物) |
| Lip Height (with standoff material where applicable) | C4_LOC_TOP_PLN |
0.261" – 0.281" | 杯口高度(带支撑物),误差影响零件配合面。 |
| Lip Thickness (Measured at four locations around CUP lip) | B3_THICK1_WALL to B3_THICK4_WALL |
0.010" – 0.017" | 杯口厚度,测4个方向。偏差大 → 杯口不对称。 |
所有变量都是经过 CMM(坐标测量机)测量的精密几何数据。
所有变量都必须在公差范围内才算 “合格”。超出任何一个 即判定为 scrap(报废)。
二、工艺流程介绍(Metal Laser Powder Bed Fusion)
Metal LPBF 的基本工艺流程

- 构建环境:
- 整个过程在一个充满氩气(argon)的 AM腔室(build chamber) 中进行,以防止金属氧化。
- 构建板(Buildplate):
- 大小为 12 x 12 x 1 英寸 的金属板,用于承载制造的所有零件。
- 每一层的步骤:
- 先铺一层薄薄的金属粉末。
- 用激光根据 CAD 图纸加热指定位置,使粉末熔化并固化成实体。
- 每一层完成后再铺下一层粉末,重复上述过程,直到完成整个三维结构。
- 支撑结构(Standoff (sacrificial material) ):
- 为了从构建板上移除零件,每个零件下方必须加上一段 牺牲材料(称为 Standoff),最后用 线切割(wire-EDM) 移除。
- 每个构建板可以构建多个组件;
- 粉末可以是纯净 virgin (pure)的或回收的recycled。在将回收物转移回源容器(source container)之前,对其进行筛分以去除熔融粉末(fused powder)。
金属增材制造 AM 的优点包括:
| 优点 | 说明 |
|---|---|
| 高吞吐量(High throughput) | 一次性构建多个零件,提高生产效率 |
| 降低成本(Reduced costs) | 精确制造、减少浪费 |
| 支持复杂结构(Part complexity) | 可制造传统机加工难以完成的几何形状 |
| 减重优化(Reduced weight) | 通过拓扑优化(topology optimization)实现结构减重 |
注意: AM 高度依赖工艺参数稳定性!
三、原材料粉末:virgin vs recycled
- Virgin powder:全新粉末,未使用过;
- Recycled powder:从上次打印剩余的粉末中筛除团聚块之后的再利用粉末。
➡️ 这两个粉末可能会在粒径、质量、纯净度上存在差异。
四、实验背景:为什么要采集这些数据?
实验目标(Experimental Objective)
本次实验是一个 前期实验(pre-production experiment),其目的是:
通过了解构建板布局参数(buildplate layout parameters)如何影响感兴趣的尺寸参数(dimensional parameters),可以确定产生最高吞吐量 highest throughput(最小化废品率 scrap rate)的布局(layout)。
| 目标 | 解释 |
|---|---|
| 表征响应变量(dimensional responses) | 主要是零件的内径、外径、高度这三项尺寸 |
| 通过实验不同的构建板布局 | 探索哪种 布局组合 可以最大化合格率、最小化报废率(scrap rate) |
| 最终目标 | 为后续“最终版布局”提供决策依据,即哪个 layout 最可靠 |
五、实验输入:板布局 buildplate layouts
本次实验测试了 多种构建板布局,如下图所示:
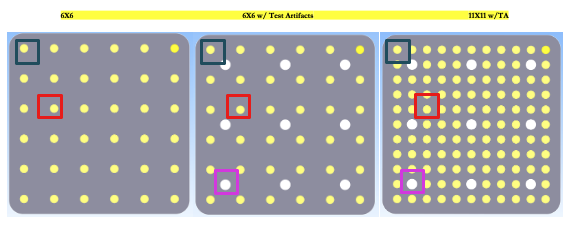
| 布局编号 | 特征 |
|---|---|
| 6x6 | 基础布局(36个零件) |
| 6x6 w/TA | 布局相同,但加入了 Test Artifacts(测试件) |
| 11x11 w/TA | 更高密度,加入了测试件,可能更考验精度和热分布 |
注:使用这些不同 layout 的目标是 比较“同样条件下”的表现差异,如粉末类型、构建位置等。
| 图示 | 说明 |
|---|---|
| 黄色圆点 | 打印的主要零件(CUP)位置 |
| 白色圆点 | 测试件(Test Artifact,TA)的位置 |
| 红框 | 一个具体对比零件(代表样本) |
| 紫框 | 测试件邻近的零件(分析 TA 的影响) |
| 左上角蓝色标记 | 定位区域(推测)用于一一比对的位置对齐 |
输入参数包括:Factors
| 因素 | 描述 |
|---|---|
| 🔲 Buildplate Loading Scheme | 本实验使用不同的“构建板布局方式”进行对比 |
| ↳ Layout & Part Proximity | 例如 6x6 或 11x11 布局,邻近零件密度不同,热积聚也不同 |
| ↳ Part Location on Plate | 每个零件在板上的具体位置(如 XY 坐标),影响打印热历史 |
| Presence of Test Artifacts (TA) | 是否存在额外的“密度测试件”,可能影响热传导或结构稳定性 |
| ♻Powder Type | 使用的是“Virgin”还是“Recycled” 粉末? |
| 限制说明 | 11x11(不含测试件)被故意排除,因为测试件影响微小,不值得独立对比 |
共包含以下 3种构建板布局:
| 布局名 | 粉末类型 | 测试件 | 构建板图 |
|---|---|---|---|
| 6x6 | Virgin | 无 | 左图 |
| 6x6 w/TA | Virgin | 有 | 中间图 |
| 11x11 w/TA | Recycled | 有 | 右图 |
没有 11x11 without TA,是因为他们认为 不加 TA 对结果影响极小,就省去了这组。
⚠️ 样本对齐方式设计为 “一对一可比”(one-to-one comparison),说明在统计分析中,你可以直接比较这 3 种 layout 中相同位置的零件尺寸变化,以排除位置影响。
- 相同编号/位置的 CUP,在不同 layout 中都出现了,便于消除“构建位置”的影响。
- 这样你就可以对比不同 layout 对同一个零件位置产生了什么不同的影响。
- 举例来说:如果红框位置在 6x6 无 TA 情况下合格,但在 6x6 with TA 情况下报废了,那就说明测试件存在影响。
六、数据总结
🟦 Virgin 粉末组:
| 布局 | 数量 | 测试件? | 总零件数 | 说明 |
|---|---|---|---|---|
| 6X6 | 3块 | 无 | 108 | 最基础实验组,对照组 |
| 6X6TA | 3块 | 有 | 108 + 27 TA | 测试件影响分析组 |
| 11X11 | -- | -- | -- | 直接被排除,不做 |
| 11X11TA | 5块 | 有 | 560 + 45 TA | Virgin 粉下的大批量打印 + TA 测试组 |
🟩 Recycled 粉末组:
| 布局 | 数量 | 测试件? | 总零件数 | 说明 |
|---|---|---|---|---|
| 11X11TA | 7块 | 有 | 784 + 63 TA | 主要用于研究“回收粉 + 大规模 + TA”组合是否合格率下降 |
表格字段详细解释
| 字段名 | 含义 |
|---|---|
| Powder | 粉末类型:Virgin(新粉)或 Recycled(回收粉) |
| Buildplate (BP) | 构建板布局方案,例如 6x6、6x6TA(with test artifacts) |
| BP Quantity | 一共做了几块这种 layout 的构建板 |
| CUPs per BP | 每块构建板制造了多少个零件(CUP) |
| Total Quantity of CUPs | 这种组合一共制造了多少个 CUP(= BP 数量 × 每块数量) |
| Total Quantity of Test Artifacts | 总共放置了多少个 TAs 测试件(只在 with TA 的构建板中) |
实验总览数据(总结):
| 合计项 | 数值 |
|---|---|
| 总 Buildplates 数量 | 18 块(= 3+3+5+7) |
| 总 CUP 数量 | 1560 个(真实零件) |
| 总 TA 数量 | 135 个(辅助测试件) |
附加题:
- 在每个构建任务完成后,都会对所用粉末进行采样。
- 使用不同尺寸的筛子(sieving drums)对粉末进行粒径分布分析。
- 这部分数据就是你用于 “Extra Credit”(加分题) 的依据。
六、数据的时间线与命名规则
实验日期范围:8月5日到9月6日,共制造了18块 buildplate
- 限制条件:不同粉末阶段(virgin/recycled)受限于可用粉末量
- 数据命名有规范的 CUP编号命名规则,可用于关联样本来源与参数组
整个实验为期约 1 个月(2025 年 8 月 5 日至 9 月 6 日)
总共制造了 18 块构建板(Buildplates),采用了两种粉末:Virgin(纯净粉) 和 Recycled(回收粉)
每种构建的类型和顺序 受限于粉末可用性
✅ Week 1(使用 Virgin Powder)
| 日期 | 编号 | 布局类型 | 说明 |
|---|---|---|---|
| Mon | A | 6X6 | 最初的 baseline 构建板 |
| Tue | B | 6X6TA | 有 test artifacts |
| Wed | C | 11X11TA | 大布局+测试件 |
| Thu | D | 11X11TA | 再次测试同类布局 |
| Fri | E | 6X6 | 回到 baseline |
➡️ Week 1 共生产 5 个 buildplates,混合 3 种 layout
✅ Week 2(继续使用 Virgin Powder)
| 日期 | 编号 | 布局类型 | 说明 |
|---|---|---|---|
| Mon | F | 6X6TA | |
| Tue | G | 6X6TA | |
| Wed | H | 11X11TA | |
| Thu | I | 6X6 | |
| Fri | J | 11X11TA |
➡️ Week 2 同样是 5 块构建板,布局种类与 Week 1 类似,形成重复样本
❌ Week 3:无实验
No testing was conducted in Week 3
推测是因为粉末不足、设备维护或计划性暂停。
🔄 Week 4 上半:Virgin Powder 最后阶段
| 日期 | 编号 | 布局类型 | 说明 |
|---|---|---|---|
| Wed | K | 11X11TA | Virgin Powder 的最后一次打印(共第 11 块) |
♻️ Week 4 下半 & Week 5:切换为 Recycled Powder
| 周 | 日期 | 编号 | 布局类型 | 说明 |
|---|---|---|---|---|
| Week 4 | Thu | L | 11X11TA | 使用 Recycled 粉末 |
| Week 4 | Fri | M | 11X11TA | Recycled |
| Week 5 | Mon | N | 11X11TA | Recycled |
| Week 5 | Tue | O | 11X11TA | Recycled |
| Week 5 | Wed | P | 11X11TA | Recycled |
| Week 5 | Thu | Q | 11X11TA | Recycled |
| Week 5 | Fri | R | 11X11TA | Recycled |
➡️ 共计 7 个构建板使用 Recycled 粉末,全部为 11X11TA 布局,形成一组稳定样本。
📌 样本编号(A–R)总览 & 布局类型匹配表
| 编号范围 | Layout | Powder | 含 TA? |
|---|---|---|---|
| A, E, I | 6X6 | Virgin | ❌ |
| B, F, G | 6X6TA | Virgin | ✅ |
| C, D, H, J, K | 11X11TA | Virgin | ✅ |
| L–R | 11X11TA | Recycled | ✅ |
➡️ 你可以据此建立变量列:sample_id,layout_type,powder_type,has_TA,week_num
八、其他建议 & 误区提醒
While data is plentiful, there are only a few replicated buildplate layouts.
也就是说:
- 数据量虽然多,但不同布局的“重复次数”少,可能不适合做复杂的假设检验。
- 你要注意“统计显著性 vs 实际显著性”(statistical vs practical significance)之间的平衡。
- 注意区分:
- 板内差异(within-buildplate variability)
- 板间差异(between-buildplate variability)
- 以及其他 扰动因素(nuisance factors)
(二)任务要求
1. 核心问题(Primary Objective):
找出哪些建造参数(build parameters)的组合可以最小化零件的报废率(scrap rate)/降低被报废的概率。
换句话说,你要构建一个可以预测“是否合格”的模型,并从中总结哪些因素最影响合格与否。
2. 样本命名规则
每个样本名(如 Aa10)由 3个部分组成:
| 组成部分 | 含义 | 举例 |
|---|---|---|
| Character 1 | **构建板编号(Buildplate)**大写字母 A–R,按打印顺序分配 | A 表示第一个 buildplate(如 6x6) |
| Character 2 | 行(Row)标识符小写字母 a–k(最多11行) | a 表示第 1 行,k 表示第 11 行 |
| Character 3/4 | 列(Column)标识符数字 1–11 | 10 表示第 10 列 |
示例 Aa10 的含义:
→ 构建板 A 上,第 a 行,第 10 列的零件。
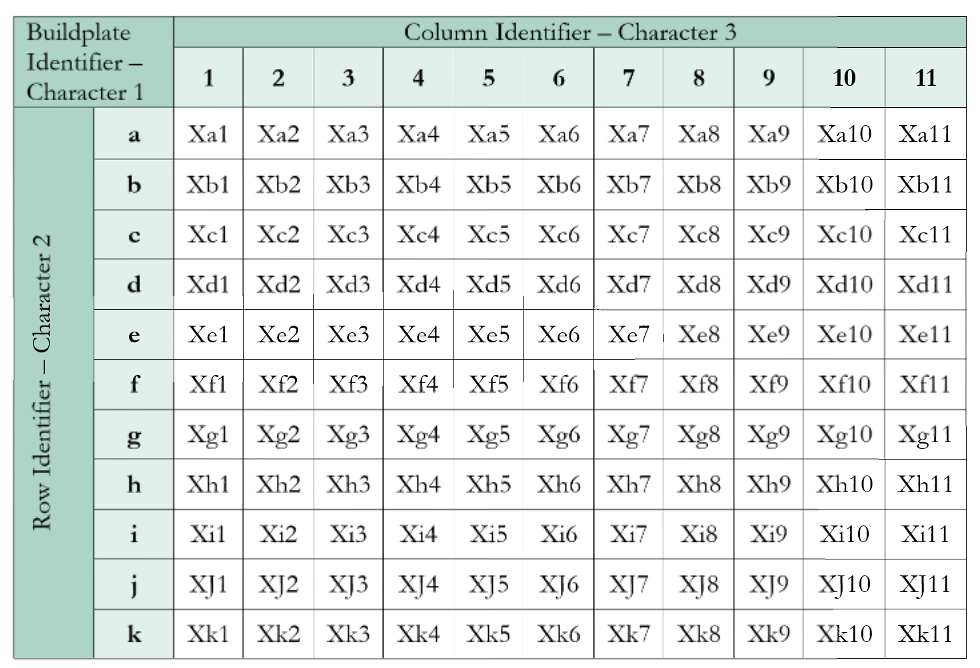
图中表格展示了一个 标准 11x11 buildplate 布局,所有零件位置从 a1 到 k11 共有 121 个格点。
| 行数 | 11(a–k) |
| 列数 | 11(1–11) |
| 总共位置 | 121 个(理论最大布局) |
| 命名样例 | Xa1, Xk11, Xh3 等 |
| X | 表示具体构建板字母(A–R) |
⚠️ 对于 6x6 布局,只使用前 6 行、前 6 列(即 a–f & 1–6),命名仍然采用同样格式。
当你处理样本数据时,建议把 CUP_ID 拆分成:
| 字段 | 示例值 | 说明 |
|---|---|---|
buildplate_id |
A | 样本来自哪块构建板(对应建模中的 group) |
row_label |
a–k |
用于空间分析 |
col_label |
1–11(字符串或数值) |
同上 |
row_num |
1–11 | 将 a–k 映射成数值:a=1, b=2, ..., k=11 |
col_num |
1–11 | 把字符串列编号变成数字 |
xy_coord |
(row_num, col_num) | 用于构建空间热图、散点图等 |
这样你就可以:
- 🌡️ 画出某个 buildplate 上各位置的 scrap 率热力图
- 📈 分析边缘 vs 中心位置的合格率
- 🔁 比较同位置不同 layout 的零件 scrap 率变化
3. 问题参数(build parameters):
输入参数(Input Features)
输入参数即为 可控的建造条件(build parameters) 和 样本本身的空间属性,这些将作为模型的自变量(features)。
- 工艺相关参数(Process / Design Parameters)
| 特征名 | 类型 | 示例 | 说明 |
|---|---|---|---|
layout_type |
类别型 | 6x6, 6x6TA, 11x11TA |
构建板布局方案 |
powder_type |
类别型 | virgin, recycled |
使用的粉末类型 |
has_TA |
布尔型 | True / False |
是否放置了 test artifacts(TA) |
buildplate_id |
类别型 | A – R |
第几块 buildplate,用于分组分析或建层次模型 |
build_week |
类别型 / 数值型 | 1–5 | 打印顺序上的时间因素 |
run_day |
类别型 | Mon, Tue, ... |
可选细化 temporal drift 分析 |
- 空间位置参数(Location Parameters)
| 特征名 | 类型 | 示例 | 说明 |
|---|---|---|---|
cup_id |
字符串 | Aa10, Rf3 |
样本唯一编号 |
row_label |
类别型 | a–k |
行号 |
col_label |
类别型 / 数值型 | 1–11 |
列号 |
row_num |
数值型 | 1–11 | 用于可视化或建模(数值化) |
col_num |
数值型 | 1–11 | 同上 |
xy_coord |
Tuple[int, int] | (3, 8) | 可构建空间热图等 |
- (可选)粉末特性参数(用于 Extra Credit)
| 特征名 | 类型 | 示例 | 说明 |
|---|---|---|---|
D50 |
数值型 | 38.2 | 粒径分布中值(中位粒径) |
PSD_bin_i |
数值型 | 每个筛孔的粒子占比 | 粒径分布的直方图分布数据 |
PSD_skewness, PSD_kurtosis |
数值型 | -0.4, 3.2 | 偏度、峰度等统计特征 |
二、输出参数(Outputs / Response Variables)
输出参数是测量的目标值,即每个样本的几何尺寸与是否合格的标签(target variable)。
- 几何测量响应值(CMM Responses)
| 特征名 | 单位 | 合格范围 | 说明 |
|---|---|---|---|
B3_DATUM_B_LOC |
inch | [0.415, 0.435] | 内径 |
B3_REF_OD |
inch | [0.445, 0.469] | 外径 |
C1_LOC_INSIDE_PLN |
inch | [0.049, 0.069] | Floor Height |
C4_LOC_TOP_PLN |
inch | [0.261, 0.281] | Lip Height |
B3_THICK1_WALL – B3_THICK4_WALL |
inch | [0.010, 0.017] | 4 个厚度测量值 |
- 派生标签(Label)
| 变量 | 类型 | 定义方式 |
|---|---|---|
is_scrap |
布尔型(0/1) | 若任一响应值超出公差范围,则为 1(报废);否则为 0(合格) |
scrap_reason |
类别型(可选) | 若你想分析失败原因,可记录是哪一项超差 |
4. 优化目标(Optimization Goal)
本次数据问题的优化目标是一个监督式分类问题(Binary Classification),目标如下:
主任务目标(Primary Objective)
找出哪些建造参数组合最小化 scrap 概率(maximize yield)
| 目标 | 类型 | 解释 |
|---|---|---|
Minimize P(is_scrap = 1) |
Classification 概率 | 通过分类模型预测零件是否报废,提高预测准确性 |
| Rank feature importance | 模型解释性分析 | 找出影响 scrap 的关键因素(如 recycled 是否更易 scrap) |
| Recommend optimal configuration | 策略建议 | 比如:建议使用 6x6TA + virgin 来获得更低 scrap 率 |
附加任务目标(Extra Credit)
分析 recycled 粉末是否影响粒径分布
| 目标 | 类型 | 方法建议 |
|---|---|---|
| 比较 virgin vs recycled 粒径分布是否显著不同 | 假设检验 | t-test, KS-test |
| 分析粒径特征(如 D50, 偏度)与 scrap 的相关性 | 回归或相关分析 | Linear regression / Pearson corr. |
| 可视化分布差异 | 直方图 / KDE 曲线 | seaborn.histplot / kdeplot |
总结:任务问题建模框架图
flowchart TD
A[Build Parameters: layout, powder, TA] --> D[Scrap Label]
B[Location on Plate: row, col] --> D
C[Geometric Measurements: dia, height, thickness] --> E{Within Tolerance?}
E -- Yes --> F[Pass - scrap = 0]
E -- No --> G[Scrap - scrap = 1]
H[Extra Credit: PSD Features] --> I[Analyze Virgin vs Recycled]4. 附加加分题(Extra Credit)
研究问题:
回收粉是否会影响粉末粒径分布?
这题的目的是让你从另一个角度分析“粉末类型”(virgin vs recycled)的影响。这需要你分析:
- 粒径分布是否显著不同?
- 是变粗了还是变细了?
- 对称性、标准差、偏度是否改变?
建议采用 直方图 + 分布重叠图 + KS检验 或 t检验 等方式验证。
5. 评分标准(Judging Criteria)分解
| 模块 | 说明 |
|---|---|
| Answers the Brief | 明确说明了哪些参数组合影响合格与否,是否解释实验流程 |
| Method/Approach | 选择的方法是否合理?是否评估过性能?结果是否可信? |
| Presentation | 是否图表清晰?是否能让非技术评委理解?是否在时间限制内? |
(三)数据结构
(base) heihe@eduroamprvnat-172-16-42-81 Sandia Datathon % tree
.
├── ~$Datathon_Kickoff_2025.pptx
├── analysis.ipynb
├── data
│ ├── AllData_PreEDM_Recycled_RowColIDs.csv
│ ├── AllData_PreEDM_Virgin_RowColIDs.csv
│ ├── recycled_volume.csv
│ ├── virgin_volume_pt1.csv
│ └── virgin_volume_pt2.csv
├── Datathon_Kickoff_2025.pptx
└── 问题讲解.md
| 文件 | 类型 | 用途 | 需要处理 |
|---|---|---|---|
AllData_PreEDM_Virgin_RowColIDs.csv |
样本维度数据 | 主任务(是否 scrap) | 合并 & 判断超差 |
AllData_PreEDM_Recycled_RowColIDs.csv |
同上 | 主任务 | 同上 |
recycled_volume.csv |
粒径分布数据(宽格式) | Extra credit | reshape 成长格式,提取批次 |
virgin_volume_pt1.csv |
同上(部分) | Extra credit | 与 pt2 合并,统一格式 |
virgin_volume_pt2.csv |
补充粒径数据 | Extra credit | 清洗列名,匹配 pt1 |
AllData_PreEDM_Virgin_RowColIDs.csv 与 AllData_PreEDM_Recycled_RowColIDs.csv
这两个文件是你分析任务的核心数据集,分别记录了使用 virgin 粉末与 recycled 粉末时,每个零件的几何检测结果与构建信息。
| 字段名 | 类型 | 示例 | 说明 |
|---|---|---|---|
Row |
字符串 | Aa1, La3 |
零件编号,含构建板、行、列(A–R 对应 buildplate) |
B3_DATUM_B_LOC |
float | 0.4171 |
Lip 内径,单位 inch,公差:[0.415, 0.435] |
B3_REF_OD |
float | 0.4476 |
Lip 外径,单位 inch,公差:[0.445, 0.469] |
C1_LOC_INSIDE_PLN |
float | 0.0539 |
Floor Height,单位 inch,公差:[0.049, 0.069] |
C4_LOC_TOP_PLN |
float | 0.2659 |
Lip Height,单位 inch,公差:[0.261, 0.281] |
B3_THICK1_WALL ~ B3_THICK4_WALL |
float ×4 | 0.0158 ... |
Lip Thickness 四个方向厚度,单位 inch,公差:[0.010, 0.017] |
Layout |
分类 | 6X6, 11X11TA |
构建板布局方案 |
BuildDate |
日期 | 8/5/2019 |
打印日期 |
Powder |
分类 | Virgin, Recycled |
粉末类型 |
MeasureSeq |
固定为 PreEDM |
测量阶段(本次任务只有这一个) | |
Nonconformity |
布尔 | FALSE |
是否报废(可能是预定义标签,但建议自己根据公差判断) |
RowID |
int | 1–11 |
样本在构建板上的行号(数字版) |
ColID |
int | 1–11 |
样本在构建板上的列号 |
PlateID |
字母 | A–R |
构建板编号 |
- 用该数据构建目标标签
is_scrap:如果任何几何指标超出范围 → scrap RowID+ColID可绘制空间热图(位置对 scrap 的影响)PlateID用于分析构建板之间的差异或做分组- 建议合并两个文件,添加新列:
SourceFile = Virgin/Recycled
data/recycled_volume.csv
该文件包含 recycled 粉末的粒径分布数据,用于 extra credit 分析。
数据结构说明(宽格式)
- 第一行:粉末批次编号(如
304L_090319),每 2 列为一组(粒径 + 对应体积分数) - 第二行:字段类型标注(交替为
Size Classes (?m)与Volume Density (%)) - 第三行往后:数据本体
| 示例列 | 含义 |
|---|---|
Size Classes (?m) |
粒径(μm) |
Volume Density (%) |
该粒径下的体积分数(%) |
- 每 2 列为一组 → 应 reshape 成长格式 DataFrame(每行为一个 sample + 粒径段 + 体积分数)
- 建议将 sample 名映射到
PlateID(如通过日期),便于和几何数据关联 - 可比较:
- Virgin vs Recycled 粉末分布曲线差异(KDE图/直方图)
- 与 scrap 概率之间的相关性
data/virgin_volume_pt1.csv 与 virgin_volume_pt2.csv
这两文件共同构成 virgin 粉末的粒径数据集,格式与 recycled 相同,但内容拆分在两个文件中。
virgin_volume_pt1.csv
- 前两行分别是 样本名 与 字段类型说明
- 后续为粒径 & 密度数据
virgin_volume_pt2.csv
- 第一行是时间戳注释型样本名,冗余
- 实际数据仍为粒径 + 密度格式
使用建议
- 与
recycled_volume.csv同理处理 - 如果样本名中包含
BP-A_2019_08_05等信息,可提取出PlateID(如A)和构建日期匹配主表 - 最终目标:统一粒径数据格式 → 建立
PlateID + D×size_bin×volume_density的长格式表