CS285-Deep Reinforcement learning-Lecture
起因
今天是25.11.5 因为实在不想学英语,外加看了一些课的时候突然发现 自己原来很想的速通课程的计划总是搁置,所以想通过记笔记的方式督促自己学cs的课程,因为实际上只是学习课程的话 重点在坚持 其实难度倒不是很大。然后同时也是最近觉得科研要保证的留痕这点 也应该放到平时的课程学习中,因此开始记笔记
一共是100个15min左右的视频,目前初步计划是每个视频记录依据到两句话 然后总的lecture1 作为一个这样、
Lecture 1 Overview
Question1 现在强化学习的制约因素
- 数据效率与可扩展性(Sample efficiency & scalability)
当前最核心的瓶颈之一是:要学出强策略,RL 往往需要极其大量的交互数据,而这些交互大多是“昂贵的”“慢的”甚至“危险的”。
表现形式:
-
Atari 或 MuJoCo 里可以用上亿步交互,但真实机器人、自动驾驶系统根本承受不了。
-
复杂任务(如长时序决策、稀疏奖励任务)往往训练几天甚至几周,仍不稳定。
代表性方向与论文:
-
模型式 RL 改善样本效率:如 DreamerV3 等工作,强调使用世界模型提高数据利用率,在多任务和不同领域有较好泛化,但训练和建模本身复杂度极高。
-
Offline RL / 数据重用:通过利用现有的离线数据(安全日志、历史操作)减少在线交互需求,但在分布偏移(distribution shift)下仍容易产生过度乐观估计和“策略崩溃”。
深层问题在于:RL 的目标是“交互数据上的决策性能”,而不是 i.i.d. 数据上的损失最小化,这让它天然比监督学习更“数据饥渴”。
- 泛化与鲁棒性(Generalization & robustness)
大多数 RL 算法在“训练环境”中表现极好,但在稍微变化的环境就迅速退化——这在现实部署中是致命的。
典型现象:
-
换个随机种子、轻微扰动动态参数、修改观测噪声,性能大幅掉落。
-
在仿真环境训练出的策略,迁移到现实世界(Sim2Real)常常严重失效。
相关研究方向:
-
Domain randomization、Invariant RL、Meta-RL 等希望让策略在“任务族”上学习更稳定的结构化表示,但目前效果距离现实复杂性还有明显差距。
-
近期工作也开始系统评测 RL 泛化能力,往往发现主流算法在 out-of-distribution 设置下非常脆弱(例如对环境外观、动力学、任务目标的微小变化都不鲁棒)。
本质上,这是“表示学习 + 分布外泛化”问题在 RL 里的极端版本。
- 奖励建模与对齐(Reward specification & alignment)
理论上,RL 只要有一个“好的奖励函数”就可以学习;但在现实中,设计或学习正确的奖励本身就是核心难题,并且直接关系到安全性与对齐问题。
主要困难:
-
奖励稀疏:只有在任务终点(成功/失败)才有反馈,学习极难启动。
-
奖励误设:稍有偏差,智能体就会学出“reward hacking”式的奇怪甚至危险行为。
-
多目标权衡:安全、效率、舒适度、公平性等多目标很难写成一个简单的标量奖励。
近期有三个比较主流的方向:
-
逆强化学习 / 奖励学习(IRL, Reward learning):从专家行为中推断隐含的奖励结构,但对示范数据质量高度敏感。
-
人类偏好学习(preference-based RL, RLHF):通过人类比较或打分学习奖励模型,目前在大语言模型对齐中非常成功,但在连续控制或复杂环境中仍不成熟,且存在“奖励模型自身偏差”的问题。
-
基于信息论或内在动机的自监督奖励(curiosity, empowerment):让智能体追求“信息增益”“多样技能”等抽象目标,但距离现实任务需求还有明显 gap。
更深刻一点讲:奖励不仅编码“任务”,还隐含“价值观与约束”,这已经超出传统 RL 设定。
- 优化稳定性与长时序信用分配(Optimization & credit assignment)
RL 的优化问题本身就比监督学习困难得多:
-
目标是期望回报,而回报是随机、延迟、非平稳的。
-
梯度估计噪声大,策略更新稍不注意就 collapse(这也是为什么 PPO、SAC 这类算法要精心设计 clipping、entropy 等 trick)。
-
长时序任务中,“早期动作对后期结果的影响”很难准确分配,credit assignment 仍是开放问题。
近期研究聚焦于:
-
设计更稳定的优化目标(如 Trust Region 类方法、分布式 RL、variance reduction 技术)。
-
借助世界模型或结构化表示,把“长时序 credit assignment”转化为更局部、更容易优化的子问题。
不过整体而言,当前RL在大规模、长地平线任务上的训练仍然十分脆弱。
- 安全与可控性(Safety & controllability)
在真实世界部署 RL 系统时,安全性是绕不过去的制约:
-
探索阶段可能触发危险操作(机器人砸坏东西、自动驾驶做出极端决策)。
-
学到的策略常常“不透明”,难以进行形式化验证。
-
多智能体环境中,策略交互可能产生非预期的复杂行为。
Safe RL 尝试把约束(如碰撞概率、能耗上界)显式写进优化目标或通过 Lagrangian 等手段处理,但在高维连续环境中,目前只能解决相对简单的约束形式,缺乏成熟的工程化方法。
总结一句话
从比较“深刻”的角度说,现在强化学习的核心制约不是**“算法是否足够聪明”**,而是:
-
如何在有限数据与计算预算下,可靠地学习复杂决策策略;
-
如何让策略在环境变化和分布偏移下仍然可泛化;
-
如何以可控、安全、对齐的方式,定义或学习“正确的目标”本身。
这三点叠加在一起,就是为什么我们在论文里看到很多漂亮的 RL 结果,但距离稳定、大规模的现实部署仍有明显差距。
Question2 制约
问题

Q3 单一算法还是多种算法综合

Lecture 2 Supervised Learning
Q1单纯模仿不行
- 行为克隆(Behavioral Cloning, BC)看起来像监督学习:给定状态 → 预测专家的动作。
- 但它不是标准监督学习,因为i.i.d. 假设(独立同分布)不成立。

但在行为克隆中:
- 模型一旦犯错,环境状态就偏离专家轨迹;
- 接着模型在“从没见过的新状态”里继续行动;
- 错误会逐步积累(compounding errors),导致崩溃。
改进方向:
- Be smart about how we collect (and augment) data
- 改进数据收集方式:让专家示范包含更多可能状态,或在训练中加入数据增强。
- Use very powerful models that make very few mistakes
- 提升模型容量(例如大模型、transformer),减少早期误差传播。
- Use multi-task learning
- 融合多任务或多专家数据,提高泛化能力。
- Change the algorithm (DAgger)
- 最重要的一点:用 DAgger (Dataset Aggregation) 替代纯行为克隆。
- DAgger 通过在模型执行时不断让专家纠正,逐步收集模型“出错”状态下的正确动作,从而克服误差累积问题。
https://gemini.google.com/share/de668b8d245f
Lecture 4
Q1 目标函数 最大化什么
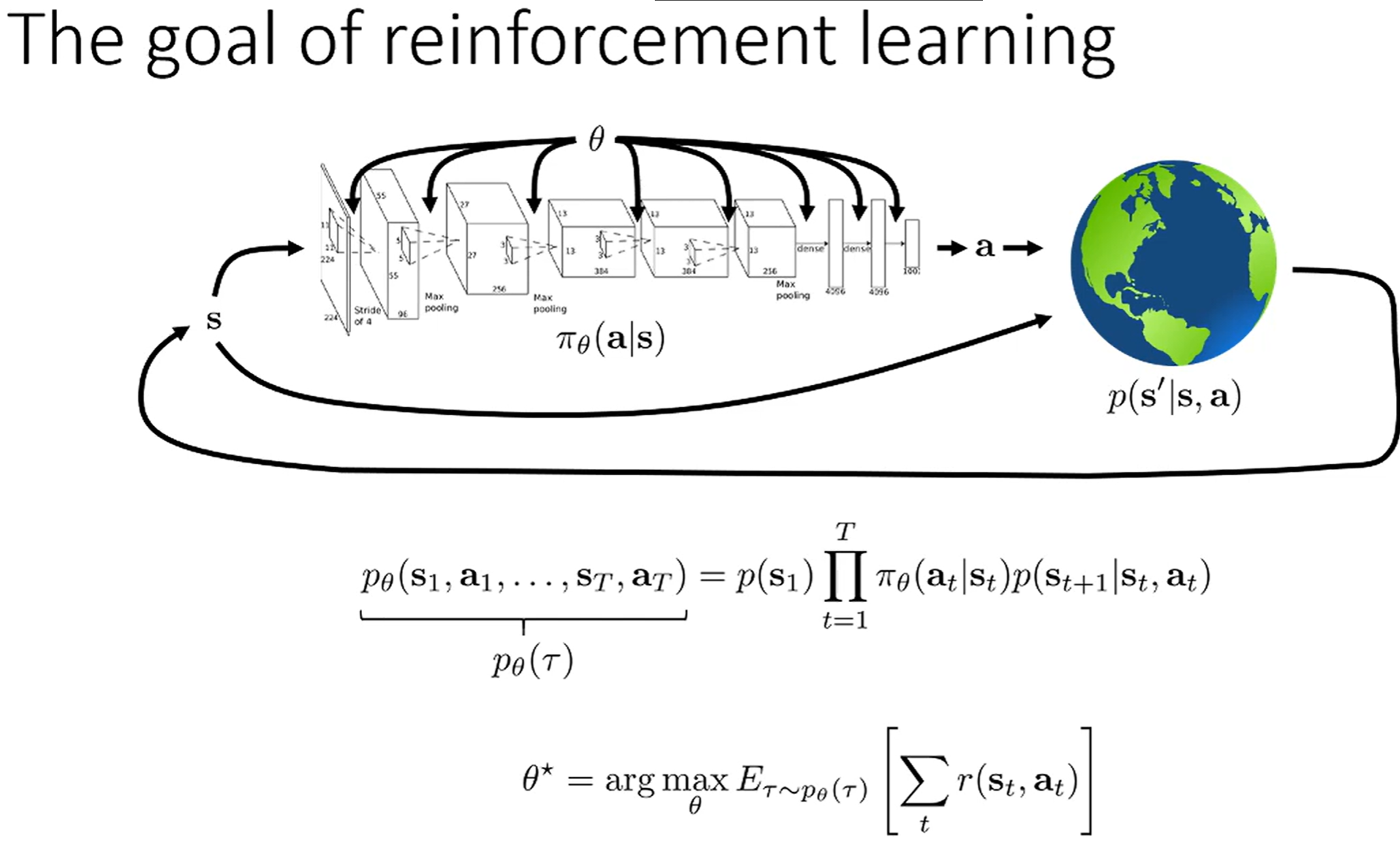
Q2 miu T 的意义

好的,你提供的这张图片非常核心,它展示了强化学习(特别是基于模型和策略梯度的方法)中关于稳态分布(Stationary Distribution的数学基础。
简单来说,这些公式在回答一个问题:“如果一个智能体(agent)按照一个固定的策略
这个“很久很久以后”的概率分布,就是稳态分布。
好的,这里是这段解释的简化版,只保留核心定义:
🎯 稳态分布:核心思想
稳态分布回答一个问题:如果智能体按一个固定策略
- 例子: 就像你按固定习惯生活,久而久之,你“宅在家”和“出门”的概率会稳定下来(比如70%/30%)。这个
就是稳态状态分布 。
📝 公式速查
-
(策略诱导的状态转移): - 解释: 打包了“策略
”和“环境 ”。它代表:“在状态 ,按策略 走一步,到 的总概率。”
-
(状态固定点): - 解释: 稳态的数学定义。意思是“当前的状态分布
,经过 转移一步后,得到的分布和 完全一样”。分布不再变化。
- 解释: 稳态的数学定义。意思是“当前的状态分布
-
(状态-动作稳态分布): - 解释: 稳态下,(处于
并且执行 ) 的概率。 - 计算: (处于
的概率) (在 时选 的概率)。
-
(状态-动作转移算子): - 解释: 描述 (s, a) 对 转移到 (s', a') 对 的概率。
- 过程: (1. 从
用 到 ) (2. 在 立刻选 )。
-
(状态-动作固定点): - 解释: 和
逻辑一样,但是是在 空间上。它说明 也是一个稳态分布( 算子的固定点)。
- 解释: 和
☀️ 简化版:天气例子核心计算
1. 定义
- 状态
: { =晴, =雨} - 动作
: { =带伞, =不带伞} - 环境
(本例中 不依赖 ): - 策略
: , ,
2. 状态分布
- 目标: 解
且 。 - 方程:
- 求解:
- 结果:
3. 状态-动作分布
- 目标: 计算
。 - 定义
对: (晴, 带伞) (晴, 不带伞) (雨, 带伞) (雨, 不带伞)
- 计算:
- 结果:
4. 状态-动作转移
- 目标: 计算
矩阵 - 行
(从 出发): - 行
(从 出发): - 结果
:
5. 验证固定点
- 目标: 验证
(矩阵乘法) 的结果仍是 。 - 第1列:
(匹配 ) - 第2列:
(匹配 ) - 第3列:
(匹配 ) - 第4列: ... = 0 (匹配
) - 结论:
成立。 是 空间马尔可夫链 的稳态分布。
计算结果:
这从数学上证明了
是这个 空间的“游戏规则”,它定义了这个 链如何一步步演化。 是这个游戏长期玩下去的“平衡状态”。 这个方程说明,一旦达到了 这个平衡状态,再按照 的规则玩下去,分布也不会再改变了。
这个的组合,就是在 空间上对 的完美复刻,它让我们可以直接在这个空间上分析 函数和策略。
 、
、
Q3 为什么看似reward +1 -1 是不可微分的 但是实际上是可微的
- 因为我们在意的是期望 然后期望是一个连续的
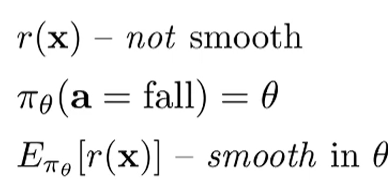
Q4 强化学习分成的几部分 每个部分花费主要在什么上面,什么时候贵 什么时候便宜
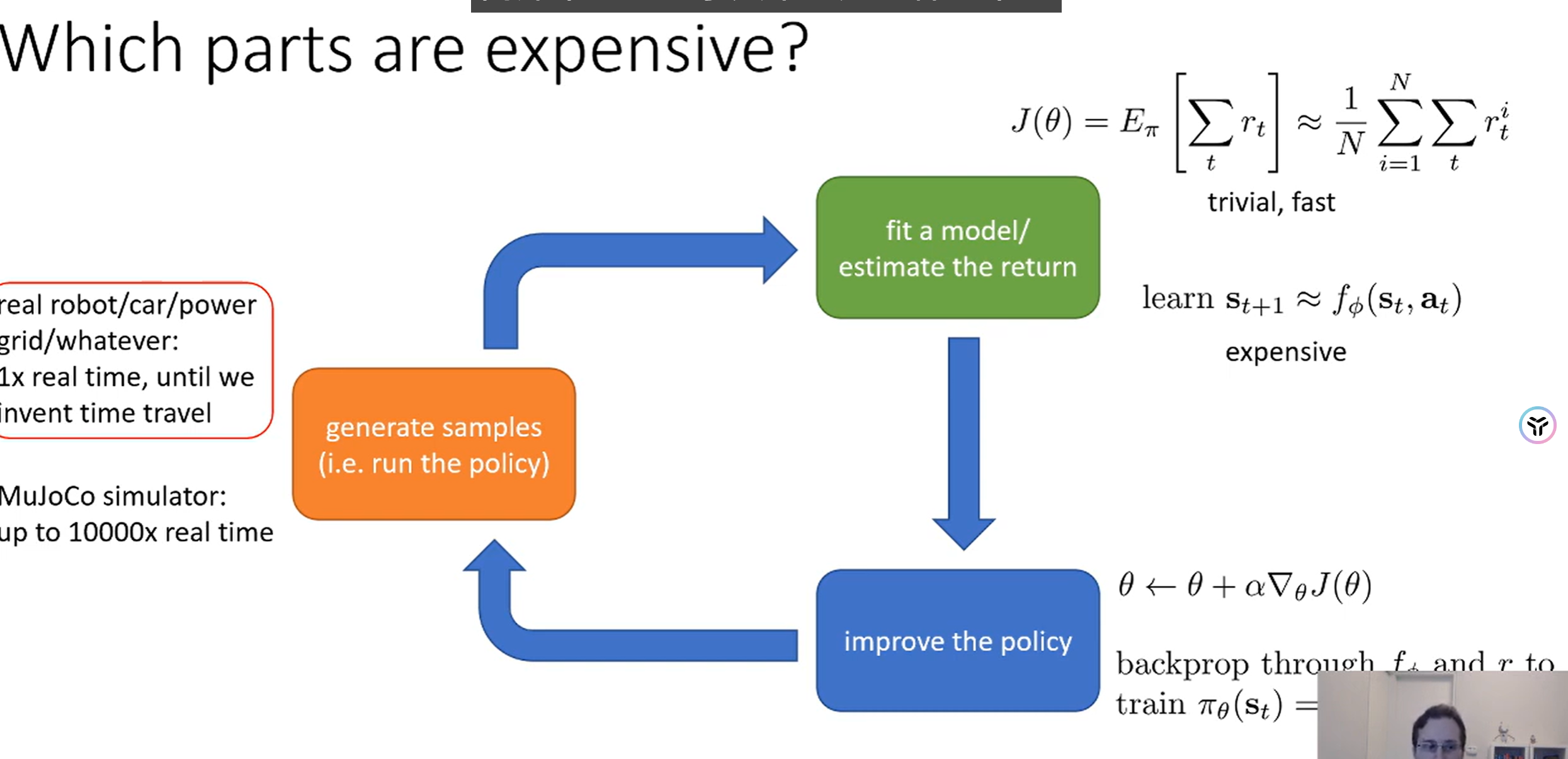
Q5 value funcition
在这张图中,
它的含义是:“从状态
=###= 详细分解
我们来看第三行的公式:
这个
-
立即奖励
- 这是你当前在状态
执行动作 后,立刻得到的奖励。
- 这是你当前在状态
-
未来所有奖励的期望
- 这部分代表了从
到 的所有未来奖励。 :这层期望是说,执行 后,环境会把你带到某个下一个状态 。我们对所有可能的 取期望。 :这层期望是说,到了 之后,你就开始按照策略 来选择动作 ,然后是 一直到 步结束。
- 这部分代表了从
总结:
这张图的最终目的是(第四行):
把一个复杂的多步求和问题
这样一来,优化的目标就清晰了:我们只需要在
-
V-函数 (Value Function)
: - 它评估的是 “一个状态
有多好”。 - 它回答的问题是:“如果我现在处于状态
,并且从这一刻开始,我完全按照策略 来行动(用 来选择 ),那么我能获得的期望总回报是多少?” - 它只依赖于状态
。
- 它评估的是 “一个状态
-
Q-函数 (Q-function)
: - 它评估的是 “在一个状态
下,执行一个特定动作 有多好”。 - 它回答的问题是:“如果我现在处于状态
,我强制先执行动作 ,然后从下一步( )开始我再按照策略 来行动,那么我能获得的期望总回报是多少?” - 它依赖于 (状态
, 动作 ) 这个组合对。
- 它评估的是 “在一个状态
-
(状态价值):你站在一个十字路口 。你有一个固定的习惯(策略 ),比如“50%概率左转,50%概率右转”。 就是你站在这里,按照你的习惯走下去,能期望得到多少好处。 -
(动作价值):你站在同一个十字路口 。 是你不管习惯,这次“选择左转”,然后从下一条路开始再按你的习惯走,能期望得到多少好处。 是你这次“选择右转”,然后从下一条路开始再按你的习惯走,能期望得到多少好处。
关键联系(图中的最后一行)
这行公式完美地总结了它们的区别:
- 状态
的价值 ... - ...等于...
- ...在该状态下,你可能采取的所有动作
的 值的期望(平均)。 - 这个“期望”是根据你的策略
来加权的。
所以:
更具体,它告诉你**“这个动作好不好”**。 更宏观,它告诉你**“这个状态好不好”**(基于你在这个状态下的平均行为)。
Q6 tradeoff alll
- sample efficiency
- stability & ease of use
- stochastic/deterministic environment
- continious states or discrete states
- episodic problems or infinite problems
- Different things are easy or hard to represent the policy/ or represent the model
Q7 efficiency vs time
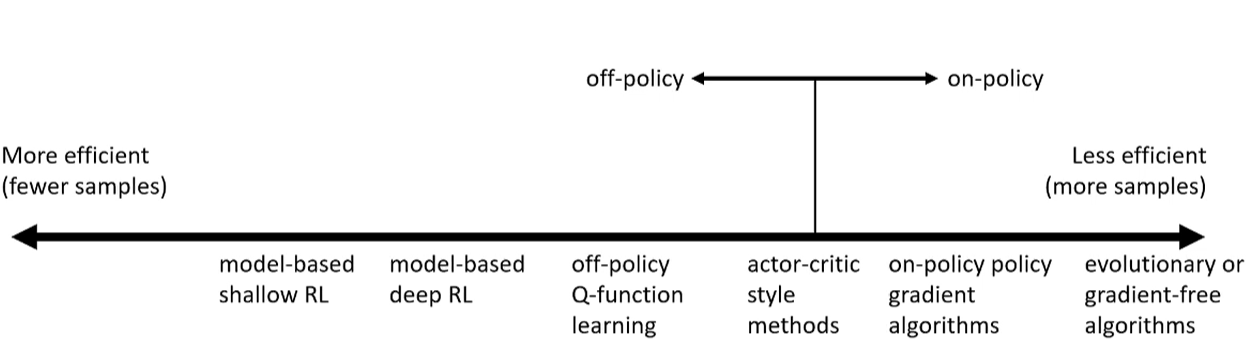
好的,这张图非常经典,它从两个关键维度对强化学习(RL)算法进行了分类。
这张图主要展示了:
- 横轴 (X轴):样本效率 (Sample Efficiency)。
- 纵轴 (Y轴):On-policy (在线策略) vs. Off-policy (离线策略)。
我们来详细解读一下。
- 横轴:样本效率 (从左到右)
这个轴衡量的是:“一个算法需要和环境交互多少次(即需要多少数据)才能学会一个好策略?”
-
左侧:More efficient (更高效)
- 含义: 只需要**很少的样本(fewer samples)**就能学会。
- 代表:Model-based (基于模型)。这类算法会尝试先“理解”环境的规则(即学习一个
模型)。一旦模型学好了,它就可以在“脑内”进行大量模拟,而不需要真正去和环境交互。 - 例子:
- model-based shallow RL:传统的基于模型的RL,不使用深度学习。
- model-based deep RL:使用深度神经网络来学习环境模型,例如 World Models。
-
右侧:Less efficient (更低效)
- 含义: 需要**海量的样本(more samples)**才能学会。
- 代表:Model-free (无模型) 和进化算法。这类算法不尝试理解环境规则,而是通过“试错”来直接学习策略或价值函数。
- 例子:
- on-policy policy gradient:比如 REINFORCE, A2C。
- evolutionary algorithms:进化算法或无梯度算法,它们完全依赖“瞎试”和“优胜劣汰”,效率最低。
-
中间地带
- off-policy Q-function learning:比如 Q-learning, DQN。它的样本效率介于两者之间。它虽然是 model-free(无模型),但它可以重复利用旧数据(Off-policy),因此效率远高于 On-policy 算法。
- actor-critic style methods:比如 A3C, DDPG, SAC。这类算法结合了策略(Actor)和价值(Critic),效率也处于中间位置。
- 纵轴:On-Policy vs. Off-Policy
这个轴描述的是:“算法在学习时,用的是什么数据?”
-
On-policy (在线策略)
- 含义: “用来学习的策略”必须和“用来收集数据的策略”是同一个。
- 比喻: 你想学打篮球,你必须自己上场打(收集数据),然后根据自己打的好坏(学习)来调整你自己的打法。你不能看乔丹的录像来学习。
- 缺点: 样本效率低。因为你每次更新策略后,你收集到的所有旧数据都作废了,必须丢掉,然后用新策略重新收集数据。
- 例子: REINFORCE, A2C, A3C, PPO(PPO在on-policy基础上做了一些改进)。
-
Off-policy (离线策略)
- 含义: “用来学习的策略”(目标策略)可以和“用来收集数据的策略”(行为策略)不是同一个。
- 比喻: 你想学打篮球,你可以观看乔丹的比赛录像(乔丹是“行为策略”),然后思考“如果换成是我(“目标策略”)在那个情况下,我会怎么做?乔丹的做法是好是坏?”
- 优点: 样本效率高。算法可以维护一个巨大的回放缓冲区 (Replay Buffer),把过去所有的经验(无论好坏,无论来自新旧策略)都存起来,反复利用这些数据进行学习。
- 例子: Q-learning, DQN, DDPG, SAC。
总结:这张图告诉我们什么?
这张图清晰地展示了RL算法的权衡 (trade-off):
-
Model-Based (左侧):样本效率最高。它们用很少的数据就能“理解世界”。但它们的缺点是,如果模型学错了(模型和真实世界有偏差),那么最终策略的效果可能很差。
-
Off-Policy Q-Learning (中间):样本效率很高。这是因为它有 Replay Buffer,可以重复利用数据。这是目前(Model-Free中)最流行和高效的方法之一。
-
Actor-Critic (中偏右):效率居中。它们通常比纯 On-Policy 算法要高效,特别是 Off-Policy 版本的 Actor-Critic (如 DDPG, SAC)。
-
On-Policy (右侧):样本效率较低。因为它们“学完就扔”数据,非常浪费。但它们通常更稳定,更容易调参。
-
Evolutionary (最右):样本效率最低。它们依赖“盲目”的变异和选择,需要天量的数据,但在某些(如梯度消失或高维动作空间)问题上可能有奇效。